



Cimpress is a fast-growing global company leading the way in mass customization. For the past few years they have been expanding rapidly both organically and through acquisition, so they’re continuously adding new locations and employees. Maintaining offices around the world means using video for face to face collaboration is extremely important to keep up with the pace of their business operations.
Every single employee has access to multiple types of video collaboration, and unsurprisingly, every single employee uses video conferencing. As a consequence, Cimpress’ IT department is expert in all facets of video when it comes to designing, deploying, and troubleshooting new systems.
[bctt tweet=”How does a #IT #helpdesk find a #videoconferencing problem without a single user complaint?” username=”vyopta”]
Recently, Cimpress brought up some specific ways they combined Real Time Monitoring and Historical Analytics to diagnose and solve an international call quality mystery at a few of their remote locations made possible by analytics
IT Notices Poor Call Quality Before Users Report An Issue
Cimpress had a couple of offices in Europe and Asia that were experiencing very similar issues. In order to integrate the new locations, they shipped endpoints and set them up to be connected as external devices (so they don’t have to fully integrate smaller offices into the WAN). Normally, this would be very difficult to monitor. However, thanks to the fact that Real Time Monitoring collects from all video infrastructure devices, they soon identified video calls that had terrible quality coming from that location – without ever receiving a complaint from users.
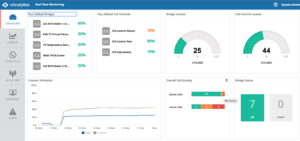
Fig 1: Real Time Dashboard with Call Quality Panel
From the dashboard, they could easily see these bad calls while they were happening and drill down to the specific participant to determine whether it was a near or far end problem. With this information they determined that packet loss was definitely happening at the far end of the call.
Proving Packet Loss For A Resolution
One data point is not enough to prove a problem, but they were able to find other calls on the same VLAN. In this case, a traveling Jabber User was in the office throughout the same month experienced the same problem. After running a couple trace routes and packet monitoring programs they were able to prove exactly where the packet loss was happening and approach the local ISP with the proof that it was between the ISP Gateway and their VCS Expressway. The ISP then responded by fixing the issue.
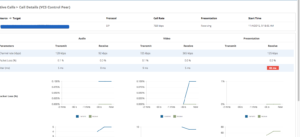
Fig 2: Individual Call Leg Details with bad Jitter
This may sound familiar to many of you who have had experience dealing with bandwidth bottlenecks, but the key difference was that they were able to do all this detective work in a single day with only minor help from the network team.
Not only did they help their new employees feel comfortable with technology in the new company, but they solved problems in less time with less impact on the user experience.

